Estimação por máxima verossimilhança em R, Julia e Python
news
code
R
Python
Julia
Author
Prof. Pedro Rafael D. Marinho
Published
September 9, 2022
Uma breve introdução
Ciência de dados é, sem dúvidas, uma área de pesquisa que permeia diversas outras ciências, estando mais intimamente relacionada com as áreas de estatística e a computação.
Eu costumo dizer aos meus alunos que um ótimo cientista de dados é o profissional que sabe mais estatística que um cientista da computação mediano e mais computação de que um estatístico mediano.
Também é importante dizer, antes de irmos ao tópico desse post, que é possível fazer ciência de dados em qualquer linguagem de programação que você domine! Claro, isso não implica que a produção de ciência de dados é igualmente fácil em qualquer linguagem que você escolha.
Dicas de linguagens
Se você me permitir te dar uma dica de qual linguagem de programação escolher, sem citar nomes, eu pediria para que você se aproximasse das linguagens que a comunidade que faz ciência de dados estão utilizando! Isso irá facilitar sua vida, pois você terá produtividade, aproveitando da infinidade de bibliotecas e frameworks disponíveis para nossa área.
Porém, se mesmo assim você quiser insistir na pergunta 😟, me tirando da região de conforto de neutralidade, eu citaria três linguagens para você escolher:
Se você está estudando algumas dessas linguagens ou domina ao menos uma delas, certamente você estará traçando um caminho congruente e terá a sua disposição um arsenal de ferramentas prontas para trabalhar com ciência de dados (bibliotecas e frameworks), i.e., você terá vários presentinhos, grátis, para poder utilizar nos seus projetos! 🎁
Cada cientista de dados, por óbvio, tem sua história pessoal, sendo comum trilharem caminhos diferentes na programação. Não se faz ciência de dados sem programação, ok? 👍
No meu caso, programo em R a muito mais tempo que em Julia e Python, algo acima de uma década. A linguagem Julia, tive o primeiro contato em 2012, (veja p. 74 de (Bezanson et al. 2017), quando surgiu a linguagem, em 2018 utilizei para construir códigos de um artigo Marinho et al. (2018), mas somente a partir da pandemia de COVID-19 foi que comecei a estudar os manuais da linguagem com um pouco mais de seriedade. A linguagem Python venho estudando mais recentemente, porém, já consigo conversar sobre temas como funções variádicas, estruturas de dados, funções varargs, closures, bibliotecas como NumPy e SciPy, pedras angulares para se fazer ciência de dados em Python, entre outros assuntos. Se você veio de R ou Julia, como foi o meu caso, e quer dominar a linguagem Python, estude a documentação oficial da linguagem que é ótima. Procure conhecer:
As estruturas de dados de Python: arrays, tuplas, listas, dicionários e conjuntos. Nesse tópico, entenda que tuplas são objetos imutáveis, listas são mutáveis e dicionários são objetos mutáveis, assim como as listas, porém possuem palavras-chave;
Estude o conceito de funções varargs, técnica muito poderosa, presente em todas às três linguagens, que permite generalizações que conduzem a códigos muito mais úteis;
Estude o conceito de closures, também presente em todas às três linguagens que estamos conversando, e em diversas outras. Esse conceito permite que suas funções possam construir novas funções;
Sobretudo, experimente a linguagem!
As linguagens podem conversar entre si 🎉
Você não precisará apenas utilizar uma mesma linguagem de programação em um projeto de ciência de dados que esteja trabalhando. Se existe como fazer algo na linguagem que você está utilizando, faça nessa linguagem! Isso irá diminuir o uso de dependências. Porém, caso algo não exista para sua linguagem e você não está afim de implementar algum método do zero, então lembre-se que você poderá importar código de outras linguagens.
Se você está
em R: você poderá importar, utilizando a biblioteca reticulate, veja Ushey, Allaire, and Tang (2022), métodos e objetos com estruturas de dados em Python onde serão convertidos para estruturas equivalentes em R. Caso queira importar códigos Julia, você poderá utilizar a biblioteca JuliaCall(Li 2019);
em Julia: você poderá importar códigos R usando a biblioteca RCall. Para importar códigos Python, você deverá utilizar a biblioteca PyCall;
em Python: você poderá chamar códigos R utilizando a biblioteca rpy2. Já para chamar códigos Julia, veja a biblioteca PyJulia.
Se você já é fluente em ao menos uma linguagem de programação, nos concentraremos nessas três citadas acima, então perceberá que dominar outra(s) linguagem(ens) será muito mais rápido. São poucas semanas de estudo necessárias para que você já consiga produzir códigos com boas práticas de programação, coisa que foi muito mais árduo no aprendizado da primeira linguagem. Claro, vez ou outra você se pegará olhando com constância os manuais dessa(s) nova(s) linguagem(ens), pois a sintaxe é nova para você e eventualmente se misturará 🧠 com a sintaxe das linguagens que você já programa. Normal!
Um dos problemas corriqueiros para quem trabalha com ciência de dados e, em particular, com inferência estatística é a obtenção dos Estimadores de Máxima Verossimilhança - EMV. Quando estamos utilizando frameworks para ciência de dados, muitas vezes essas estimações ocorrem por baixo do pano. Há diversas situações em que estimadores com boas propriedades estatísticas precisam ser utilizados, e os EMV são, de longe, os mais utilizados.
Na área de machine learning, por exemplo, se o que está sendo otimizado por “baixo dos panos” não é uma função de log-verossimilhança, existirá alguma função objetivo que precisará ser maximizada ou minimizada, utilizando métodos de otimizações globais; métodos de Newton e quasi-Newton, os mesmos que utilizaremos para obtenção das estimativas obtidas pelos EMV, aqui nessa postagem. Seguindo com outro exemplo, na área de redes neurais alimentadas para frente (feedforward), aplicadas a problemas de regressão ou classificação, existe uma função objetivo que considerará os pesos sinápticos da arquitetura da rede com \(n\) conexões, isto é, existirá uma função \(f(y, w_1, w_2, \cdots)\), em função dos pesos sinápticos \(w_i, i = 1, ..., n\) e da saída esperada. Como \(y\) é conhecido (saída esperada da rede), para que a rede esteja bem ajustada, será preciso encontrar um conjunto ótimo de valores \(w_i\) que minimize essa função. Isso é feito pelo algoritmo backpropagation utiliza métodos de otimização não-linear para encontrar o mínimo global de uma função objetivo.
Em algum momento você tem que saber otimizar funções
Em fim, você em algum momento, no seu percurso na área de ciência de dados, irá ter que otimizar funções. Quando digo otimizar, em geral, me refiro a maximizar ou minimizar uma função objetivo. Escolher entre minimizar ⬇️ ou maximizar ⬆️ dependerá da natureza do problema em questão.
Você, como um cientista de dados que é, ou que almeja ser, será o responsável em descobrir se o que precisará fazer será maximizar ou minimizar uma função. Sobretudo, você que precisará saber qual função deverá otimizar! Isso vai além da programação. Portanto, procure sempre entender o problema e conhecer os detalhes das metodologias que deseja utilizar. 🧠
Funções objetivos irão sempre aparecer na sua vida! 👍
Estimadores de máxima verossimilhança - EMV
Para não ficarmos apenas olhando códigos de programação em três linguagens distintas (R, Julia e Python), irei contextualizar um simples problema: o problema de encontrar o máximo da função de verossimilhança. Serei muito breve! 🎉
A maior barreira 🧱 de uma implementação consistente!
A grande barreira que limita a nossa implementação, quando já dominamos ao menos uma linguagem de programação, é não saber ao certo o que desejamos implementar.
É por isso que irei contextualizar, de forma breve, um problema comum na estatística e ciência de dados; o problema de otimizar uma função objetivo. Mais precisamente, desejaremos obter o máximo da função de verossimilhança.
Para simplificar a teoria, irei considerar algumas premissas:
Você tem algum conhecimento de probabilidade;
Considerarei o caso univariado, em que teremos uma única variável aleatória - v.a. que denotarei por \(X\);
A variável aleatória - v.a. \(X\) é contínua, portanto suas observações podem ser modeladas por uma função densidade de probabilidade - fdp\(f\), tal que \(f_X(x) \geq 0\) e \(\int_{-\infty}^{+\infty}f_X(x)\, \mathrm{d}x = 1\).
Na prática, o problema consiste em, por meio de um conjunto de dados, fixarmos uma fdp \(f_X\). Daí, desejaremos encontrar os parâmetros de fdp que faz com que \(f_X\) melhor se ajuste aos dados. Os parâmetros \(\alpha\) e \(\beta\) que fará com que \(f_X\) melhor se ajuste aos dados poderão ser obtidos maximizando a função de verossimilhança \(\mathcal{L}\) de \(f_X\), em relação a \(\alpha\) e \(\beta\), definida por:
\[
\mathcal{L}(x, \alpha,\beta) = \prod_{i = 1}^n f_{X_i}(x, \alpha, \beta).
\tag{1}\] Para simplificar as coisas, como \(\log(\cdot)\) é uma função monótona, então, os valores de \(\alpha\) e \(\beta\) que maximizam \(\mathcal{L}\) serão os mesmos que maximizam \(\log(\mathcal{L})\), ou seja, poderemos nos concentrar em maximizar:
Suponha que \(X \sim Weibull(\alpha = 2.5, \beta = 1.5)\), ou seja, que os dados que chegam a sua mesa são provenientes de uma v.a. \(X\) que tem observações que seguem a distribuição \(Weibull(\alpha = 2.5, \beta = 1.5)\). Essa será nossa distribuição verdadeira!
Na prática, você apenas conhecerá os dados! Será você, como cientista de dados, que irá supor alguma família de distribuições para modelar os dados em questão. 🥴
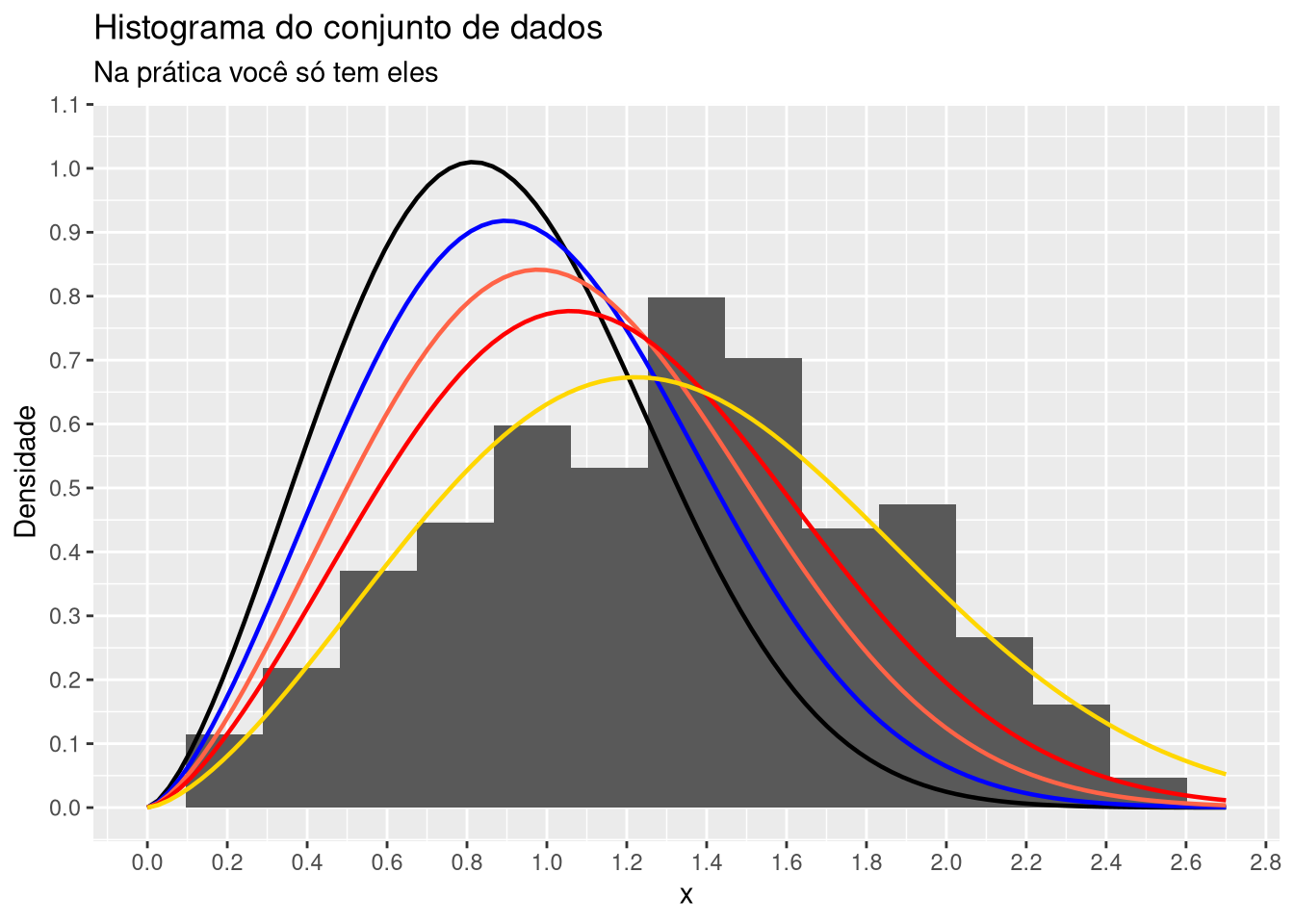
Vamos supor que você, assertivamente, escolhe a família Weibull de distribuições para modelar o seu conjunto de dados (você fará isso olhando o comportamento dos dados, por exemplo, fazendo um histograma). Existem testes de aderências para checar o quanto uma distribuição se ajusta a um conjunto de dados. Não entraremos nesse assunto aqui!
Quer ver o código do gráfico? Clique aqui!
library(ggplot2)# Quantidade de elementosn <- 550L# Parâmetro de formaalpha <-2.5# Parâmetro de escalabeta <-1.5# Fixando uma semente, de forma a sempre obtermos a mesma amostraset.seed(0)dados <-data.frame(x =seq(0, 2, length.out = n),y_rand =rweibull(n, shape = alpha, scale = beta) )dados |>ggplot() +geom_histogram(aes(x = y_rand, y = ..density..), bins =15) +ggtitle(label ="Histograma do conjunto de dados",subtitle ="Na prática você só tem eles" ) +labs(y ="Densidade",x ="x" ) +scale_x_continuous(limits =c(0, 2.7),n.breaks =15 ) +scale_y_continuous(limits =c(0, 1.05),n.breaks =15 ) +geom_function(fun = dweibull,args =list(shape = alpha, scale =1),size =0.8 ) +geom_function(fun = dweibull,args =list(shape = alpha, scale =1.1),color ="blue",size =0.8 ) +geom_function(fun = dweibull,args =list(shape = alpha, scale =1.2),color ="tomato",size =0.8 ) +geom_function(fun = dweibull,args =list(shape = alpha, scale =1.3),color ="red",size =0.8 ) +geom_function(fun = dweibull,args =list(shape = alpha, scale = beta),color ="gold",size =0.8 )
Note que todas as funções densidades de probabilidades - fdps plotadas no histograma apresentado no gráfico acima são densidades da família Weibull de distribuições. O que difere uma da outra são os valores de \(\alpha\) e \(\beta\), respectivamente. Não basta escolher uma família de distribuições adequada. Precisamos escolher (estimar) adequadamente os parâmetros que indexam a distribuição, sendo o método de máxima verossimilhança, a metodologia estatística que nos ajudam a fazer uma ótima escolha, conduzindo as estimativas que são provenientes de estimadores com boas propriedades estatísticas.
Lembre-se, para obter essas estimativas, temos que maximizar a Equation 1, ou equivalentemente a Equation 2.
No gráfico acima, é possível visualmente perceber que a curva em amarelo é a que melhor aproxima o comportamento dos dados. Não iremos fazer testes de adequação!
De fato, essa é a curva da distribuição verdadeira, i.e., é a curva da fdp de \(X \sim Weibull(\alpha = 2.5, \beta = 1.5)\). Por sinal, ainda não coloquei a equação da fdp de \(X\). Segue logo abaixo:
\[f_X(x) = (\alpha/\beta)(x/\beta)^{\alpha - 1}\exp[{-(x/\beta)^\alpha}],\] com \(x\), \(\alpha\) e \(\beta > 0\).
Implementações
Agora que já conhecemos \(f_X\) e \(\ell(\cdot)\) (“função objetivo”), poderemos colocar as “mãos na massa” no teclado.
E os dados?
Os dados serão gerados aleatoriamente, em cada uma das linguagens (R, Julia e Python). Sendo assim, muito provavelmente não serão os mesmos dados, em cada linguagem, pois a sequência gerada que corresponderá aos nossos dados dependerá das implementações dos geradores de números pseudo-aleatórios de cada linguagem. Porém, os resultados das estimativas devem convergir para valores próximos a \(\alpha = 2.5\) e \(\beta = 1.5\), nas três linguagens. Por isso, não irie comparar, inicialmente, os resultados das estimativas obtidas. Ao final da postagem, farei uma sucinta comparação.
Irei colocar comentários nos códigos para que você possa estudar cada um deles. Nada em excesso!
Antes irei colocar uma observação para a linguagem Python. As pedras angulares para computação científica em Python são as bibliotecas NumPy e Scipy. Por que elas são úteis?
Numpy: é uma biblioteca de código aberto iniciada em 2005 e que possui diversos métodos (funções) numéricas comumente utilizadas na computação científica. Há diversos métodos para operar sobre arrays, vetorização, geração de números pseudo-aleatórios, entre outras coisas. Consulte mais detalhes em https://numpy.org/doc/stable;
Scipy: trata-se de outra biblioteca importante que contém implementações de métodos e algoritmos fundamentais para computação científica, como métodos de integração, interpolação, otimização, entre diversas outras metodologias. Consulte outros detalhes em https://scipy.org.
Iremos utilizar ambas as bibliotecas. Basicamente a Numpy será utilizada para vetorização de código, trabalhar com arrays e gerar observações da distribuição Weibull. Nesse último ponto, especificamente, a biblioteca Numpy implementa a função que gera observações de uma distribuição Weibull, onde a distribuição Weibull só tem um parâmetro. Consulte detalhes em https://numpy.org/doc/stable/reference/random/generated/numpy.random.weibull.html.
No link você verá que o que é implementado pelo método random.weibull é gerar observações de \(X = [-\log(U)]^{1/\alpha} \sim Weibull(\alpha)\), com \(U\) sendo um v.a. uniforme no intervalo (0,1] . Daí, para gerar observações da distribuição \(Weibull(\alpha, \beta)\), teremos que multiplicar o resultado de random.weibull pelo valor de \(\beta\). Porém, com pouco código, podemos construir uma função para gerar observações da \(Weibull(\alpha, \beta)\).
Eu olhando para um pouco de malabarismo de código em Python.
Isso é um pouco estranho, mas tudo bem, sabemos programar!
Ter que multiplicar as observações geradas de uma distribuição que deveria ter, em sua definição, dois parâmetros me parece estranho! Perceba que no código de Python foi preciso fazer definir a função random_weibull, em que foi preciso considerar beta * np.random.weibull(alpha, n) para se ter observações Weibull com valores de \(\beta\) diferente de 1. É fácil adaptar, mais o designer não é legal, na minha opinião.
Afinal de contas, é muito mais conveniente alterar o comportamento e resultados de uma função passando argumentos para a função, e não fazendo as alterações fora dela. É esse o papel dos argumentos, não? Se o usuário tivesse interesse que \(\beta = 1\), como ocorre em random.weibull ele poderia especificar isso como argumento passados à função, certo?
Comportamentos mais convenientes são observados em R e Julia, afinal de contas, elas surgiram com o foco na computação científica. R é mais voltada para ciência de dados e aprendizagem de máquina. Já Julia, além dos mesmos focos de R, também é uma linguagem de propósito geral, assim como Python é em sua essência.
Note que essa minha crítica não é a linguagem Python. Refere-se tão somente ao método random.weibull e alguns outros que seguem esse designer de implementação. Python é uma ótima linguagem que vem melhorando o seu desempenho nas novas versões. Veja as novidades de lançamento do Python 3.11, que alcançou melhorias no desempenho computacional entre 10-60% quando comparado com Python 3.10. Algo em torno de 1.25x de aumento no desempenho, considerando o conjunto de benchmarks padrão que o comitê de desenvolvimento da linguagem utiliza.
Agora, sim, vamos aos três códigos completos para a solução do problema que motiva o título desse post.
Nas três linguagens, utilizarei os mesmo conceitos importantes de implementação que conduzem a códigos mais generalizados e a um melhor reaproveitamento de código:
Note que utilizo o conceito de funções com argumentos variáveis, também chamadas de funções varargs. Perceba que a função log_likelihood não precisa ser reimplementada novamente para outras funções densidades. A função densidade de probabilidade é um argumento dessa função que denominei de log_likelihood nos três códigos (R, Python e Julia). Precisamos de funções com operadores varargs, tendo em vista que não conhecemos o número de parâmetros da fdp que o usuário irá passar como argumento. Funções com argumentos varargs é uma técnica muito poderosa. Utilizei esses conceitos em Python e Julia, devido a natureza das funções de otimizações das duas linguagens, em que em seus designers permitem que os argumentos a serem otimizados da função objetivo seja de número variável. As funções varargs de R são definidas pelo operador dot-dot-dot (...). O designer da função optim() de R incluem o parâmetro dot-dot-dot, para argumentos extras que eventualmente possam existir na função objetivo. ⚡
Note que não é preciso obter analiticamente a expressão da função de log-verossimilhança. Não há sentido nisso, tendo em vista que o nosso objetivo é simplesmente obter as estimativas numéricas para \(\alpha\) e \(\beta\) . É muito mais útil ter uma função genérica que se adéque a diversas outras situações!
Outro conceito poderoso e que te leva a implementações consistentes é entender o funcionamento das funções anônimas, também conhecidas como funções lambda.
Foi utilizado como método de otimização (minimização), o método BFGS. Escrevi a respeito dos métodos de quasi-Newton, classe de algoritmos que o método de Broyden–Fletcher–Goldfarb–Shanno - BFGS pertencem, nos materiais que disponibilizo aos meus alunos na disciplina de estatística computacional que leciono no Departamento de Estatística da UFPB. Se quiser um pouco mais de detalhes a respeito dos métodos de Newtone quasi-Newton, clique aqui.
Minimizar ou maximizar?
Alguns algoritmos de otimização são definidos para minimizar uma função objetivo, como é o caso da maioria das implementações dos métodos de busca global, onde se encaixa o método BFGS. Mas não tem problema, uma vez que minimizar, \(-f\) equivale a maximizar \(f\), em que \(f\) é uma dada função objetivo.
# Quantidade de observaçõesn <- 250L# Parâmetros que especificam a distribuição verdadeira, i.e., distribuição# da variável aleatória cujo os dados são observações.alpha <-2.5beta <-1.5# Fixando uma semente para o gerador de números pseudo-aleatórios.# Assim, conseguimos, toda vez que rodamos o código, reproduzir # os mesmos dados.set.seed(0)# Gerando as observações. Esse será o conjunto de dados que você tera para # modelar.dados <-rweibull(n = n, shape = alpha, scale = beta)pdf_weibull <-function(x, par){ alpha <- par[1] beta <- par[2] alpha/beta * (x/beta)^(alpha-1) *exp(-(x/beta)^alpha)}# Checando se a densidade de pdf_weibull integra em 1area =integrate(f = pdf_weibull, lower =0, upper =Inf, par =c(2.5, 1.5))# Em R, o operador dot-dot-dot (...) é utilizado para definir# quantidade variádica de argumentos. Assim, log_likelihood é# uma função vararg.log_likelihood <-function(x, pdf, par)-sum(log(pdf(x, par)))result <-optim(fn = log_likelihood,par =c(0.5, 0.5),method ="BFGS",x = dados,pdf = pdf_weibull)# Imprimindo os valores das estimativas de máxima verossimilhançacat("Valores estimados de alpha e beta\n")
Valores estimados de alpha e beta
cat("--> alpha: ", result$par[1], "\n")
--> alpha: 2.834629
cat("--> beta: ", result$par[2], "\n")
--> beta: 1.456748
usingDistributionsusingRandomusingOptimusingQuadGK# Quantidade de observaçõesn =250;# Parâmetros que especificam a distribuição verdadeira, i.e., # da fdp da v.a. cujos os dados são observações.α =2.5;β =1.5;# Fixando um valor de sementeRandom.seed!(0);# Gerando um array de dados com distribuição Weibull(α, β)dados =rand(Weibull(α,β), n);# Função densidade de probaiblidade de uma v.a. # X ∼ Weibull(α, β)functionpdf_weibull(x, par = (α, β)) α, β = par.α, par.β @. α/β * (x/β)^(α-1) *exp(-(x/β)^α)end;# Checando se a integral no suporte de pdf_weibull integra em 1area, error =quadgk(x ->pdf_weibull(x, (α = α, β = β)), 0, Inf);# Escrevendo a função log_likelihood que em julia denotarei por# ℓ, tendo em vista que podemos fazer uso de caracteres UTF-8 # nessa linguagem. functionℓ(x, pdf, par...)-sum(log.(pdf(x, par...)))end;# Encontrando as estimativas de máxima verossimilhança usando a# biblioteca Optimemv =optimize( x ->ℓ(dados, pdf_weibull, (α = x[1], β = x[2])), [0.5, 0.5],LBFGS()); emv_α, emv_β = emv.minimizer;# Imprimindo o resultadoprint("Valores estimados para α e β\n")
Valores estimados para α e β
print("--> α: ", emv_α, "\n")
--> α: 2.4472234393032837
print("--> β: ", emv_β, "\n")
--> β: 1.4480344422787308
import numpy as npimport scipy.stats as statimport scipy.integrate as inteimport scipy.optimize as opt# Valores da distribuição verdadeiraalpha =2.5beta =1.5# Número de observações que irão compor nossos dadosn =250# Implementando a função random_weibull, em que os parâmetros# que indexam a distribuição são argumentos da função. Tem mais# sentido ser assim, não?def random_weibull(n, alpha, beta):return beta * np.random.weibull(alpha,n)# Escrevendo a funçãp densidade de probabilidade da Weibull# na reparametrização correta.def pdf_weibull(x, param): alpha = param[0] beta = param[1]return alpha/beta * (x/beta)**(alpha-1) * np.exp(-(x/beta)**alpha)# Testando se a densidade integra em 1área =round(inte.quad(lambda x, alpha, beta: pdf_weibull(x, param = [alpha, beta]),0, np.inf, args = (1,1))[0],2)# Implementando uma função genérica que implementa a função objetivo# (função de log-verossimilhança) que iremos maximizar. Essa função # irá receber como argumento uma função densidade de probabilidade.# Não é preciso destrinchar (obter de forma exata) a função de # log-verossimilhança!# A função de log-verossimilhança encontra-se multiplicada por -1# devido ao fato da função que iremos fazer otimização minimizar # uma função função objetivo. Minimizar -f equivale a maximizar f.# Lembre-se disso!def log_likelihood(x, pdf, *args):return-np.sum(np.log(pdf(np.array(x), *args)))# Gerando um conjunto de dados com alpha = 2.5 e beta = 1.5. Essa # é nossa distribuição verdadeira, i.e., é a distribuição que gera# que gerou os dados que desejamos ajustar.# Precisamos fixar uma semente, uma vez que queremos os mesmos dados# toda vez que rodamos esse código. np.random.seed(0)dados = random_weibull(n = n, alpha = alpha, beta = beta)# Miminimizando a função -1 * log_likelihood, i.e., maximizando# a função log_likelihood.alpha, beta = opt.minimize( fun =lambda*args: log_likelihood(dados, pdf_weibull, *args), x0=[0.5, 0.5]).x# Imprimindo os valores das estimativas de máxima verossimilhançaprint("Valores estimados de alpha e beta\n")
Valores estimados de alpha e beta
print("--> alpha: ", alpha, "\n")
--> alpha: 2.541634329050904
print("--> beta: ", beta, "\n")
--> beta: 1.480430581806816
Visualização gráfica
Vamos agorar comparar graficamente as estimativas obtidas pelos métodos de otimização (BFGS) considerando as bibliotecas fornecidas nas três linguages. Para uma melhor visualização, utilizaremos o gráfico de curvas de níveis. Perceba que \(\mathcal{L}\) possui como variáveis os parâmetros \(\alpha\) e \(\beta\), sendo \(x\) o conjunto de dados que é fixo. Assim, consiguiremos visualizar em 2D o comportamento de \(\mathcal{L}\).
Para que possamos visualizar graficamente e comparar as estimativas obtidas nas três linguagens, será preciso que o conjunto de dados seja idêntico nos processos de otimização realizados em R, Julia e Python.
Para acessar o conjunto de dados, clique aqui. O conjunto de dados possui \(n = 500\) observações. Ainda continuarei considerando \(\alpha = 2.5\) e \(\beta = 1.5\).
Perceba que foi obtido ótimas estimativas pelo método BFGS, nas três linguagens. Note que tive que colocar um ponto maior que o outro, para que eles não ficassem totalmente sobrepostos, e assim pudéssemos visualizar.
Conclusões
Espero que esse post tenha conseguido exemplificar como poderemos implementar a solução de um problema de estimação por máxima verossimilhança, utilizando as linguagens de programação R, Python e Julia. Abordamos conceitos interessantes como funções varargs e funções anônimas, além de algumas estruturas de dados e bibliotecas.
Nos primeiros códigos, foram observados ótimas estimativas, muito embora elas não são comparáveis, tendo em vista que os conjuntos de dados gerados aleatoriamente foram distintos, por conta da natureza de implementação das funções para geração de números pseudo-aleatórios, disponíveis em cada uma das linguagens comparadas. Foi escolhido fazer dessa forma, para que fosse possível abordar o problema de geração de números pseudo-aleatórios em cada linguagem.
No fim, foi realizado uma comparação mais justa, onde o mesmo conjunto de dados foi considerado para a produção das curvas de níveis, úteis para visualizar em uma imagem 2D a qualidade das estimativas. No gráfico de curvas de níveis, é possível observar a sobreposição das estimativas obtidas utilizando R, Python e Julia.
Também é possível perceber que otimizar uma função objetivo é fácil, independentemente da linguagem, sendo possível conseguir códigos concisos e eficientes.
Todos os gráficos dessa postagem foram construídos em R, através da biblioteca Wickham (2016). Caso queira construir gráficos em Python ou em Julia, considere as seguintes cito a biblioteca seaborn de Python e a biblioteca Makie de Julia. São apenas sugestões, tendo em vista que há diversas outras alternativas interessantes.
Referências
Bezanson, Jeff, Alan Edelman, Stefan Karpinski, and Viral B. Shah. 2017. “Julia: A Fresh Approach to Numerical Computing.”SIAM Review 59 (1): 65–98. https://doi.org/10.1137/141000671.
Marinho, Pedro Rafael Diniz, Gauss M. Cordeiro, Fernando Peña Ramírez, Morad Alizadeh, and Marcelo Bourguignon. 2018. “The Exponentiated Logarithmic Generated Family of Distributions and the Evaluation of the Confidence Intervals by Percentile Bootstrap.”Brazilian Journal of Probability and Statistics 32 (2). https://doi.org/10.1214/16-bjps343.
R Core Team. 2022. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.